C Hash Tables: Build a Lightning-Fast Lookup Table From Scratch
Table of Contents
Why Hash Tables?
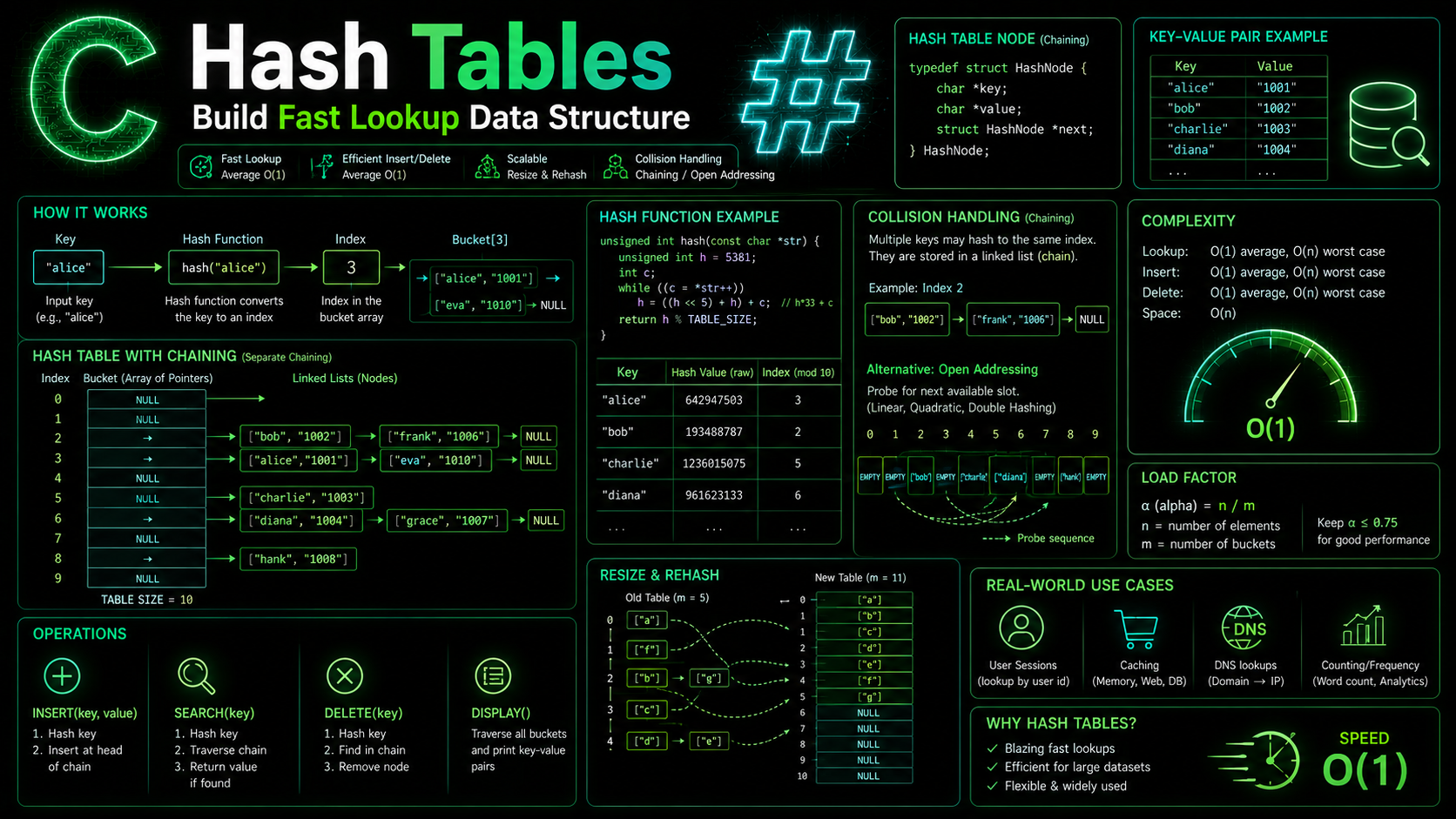
Imagine you have a phone book with 10,000 names. To find someone in an array, you’d scan through entries one by one — O(n). With a sorted array and binary search, you’d get O(log n). But a hash table? O(1) average case. That’s constant time, regardless of whether you have 100 or 10 million entries.
Hash tables are the backbone of dictionaries in Python, objects in JavaScript, and HashMap in Java. In C, we don’t get one for free — we build it ourselves. And honestly, building one teaches you more about how computers actually work than using a library ever could.
Before diving in, make sure you’re comfortable with C Pointers and C Dynamic Memory Allocation, since we’ll be using both heavily.
How Hashing Works
A hash table works in three steps:
- Take a key (usually a string)
- Run it through a hash function to produce a number
- Use that number as an index into an array of “buckets”
The hash function converts arbitrary data into a fixed-range integer. For a table with 64 buckets, a key like "email" might hash to index 23. Next time you look up "email", the same function produces 23 again, and you go straight to bucket 23. No scanning required.
The catch? Two different keys might hash to the same index. That’s called a collision, and how you handle it determines the quality of your hash table.
Hash Functions: djb2 and FNV-1a
A good hash function distributes keys uniformly across buckets. Here are two battle-tested options.
djb2 (Daniel J. Bernstein)
This function has been around since the early 1990s and is remarkably effective for its simplicity:
unsigned long hash_djb2(const char *str) {
unsigned long hash = 5381;
int c;
while ((c = *str++)) {
hash = ((hash << 5) + hash) + c; // hash * 33 + c
}
return hash;
}The magic number 5381 and multiplier 33 were chosen empirically — they produce good distribution for typical string data.
FNV-1a (Fowler-Noll-Vo)
FNV-1a is slightly better at distributing similar strings (like “abc” vs “abd”):
unsigned long hash_fnv1a(const char *str) {
unsigned long hash = 2166136261u; // FNV offset basis
while (*str) {
hash ^= (unsigned char)*str++;
hash *= 16777619u; // FNV prime
}
return hash;
}Both produce a large number. To get an array index, take the result modulo the table size: index = hash(key) % table_size.
Collision Handling with Chaining
When two keys hash to the same bucket, chaining stores them in a linked list at that bucket. It’s the most common collision resolution strategy.
Picture an array of 8 buckets. Keys “apple” and “grape” both hash to bucket 3. Instead of overwriting, bucket 3 holds a linked list: apple -> grape -> NULL. To find “grape”, you hash to bucket 3, then walk the list comparing keys.
Complete Hash Table Implementation
Here’s a full, production-quality hash table with chaining. This is the kind of implementation you’d actually use in a real C project.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <stdbool.h>
#define INITIAL_CAPACITY 64
// Each entry in the chain
typedef struct Entry {
char *key;
char *value;
struct Entry *next;
} Entry;
// The hash table itself
typedef struct {
Entry **buckets;
int capacity;
int count;
} HashTable;
// --- Hash function ---
static unsigned long hash_djb2(const char *str) {
unsigned long hash = 5381;
int c;
while ((c = *str++))
hash = ((hash << 5) + hash) + c;
return hash;
}
// --- Create ---
HashTable *ht_create(int capacity) {
HashTable *ht = malloc(sizeof(HashTable));
if (!ht) { perror("malloc"); exit(EXIT_FAILURE); }
ht->capacity = capacity;
ht->count = 0;
ht->buckets = calloc(capacity, sizeof(Entry *));
if (!ht->buckets) { perror("calloc"); exit(EXIT_FAILURE); }
return ht;
}
// --- Set (insert or update) ---
void ht_set(HashTable *ht, const char *key, const char *value) {
unsigned long index = hash_djb2(key) % ht->capacity;
// Check if key already exists
Entry *current = ht->buckets[index];
while (current) {
if (strcmp(current->key, key) == 0) {
// Update existing value
free(current->value);
current->value = strdup(value);
return;
}
current = current->next;
}
// Insert new entry at head of chain
Entry *entry = malloc(sizeof(Entry));
if (!entry) { perror("malloc"); exit(EXIT_FAILURE); }
entry->key = strdup(key);
entry->value = strdup(value);
entry->next = ht->buckets[index];
ht->buckets[index] = entry;
ht->count++;
}
// --- Get ---
char *ht_get(HashTable *ht, const char *key) {
unsigned long index = hash_djb2(key) % ht->capacity;
Entry *current = ht->buckets[index];
while (current) {
if (strcmp(current->key, key) == 0)
return current->value;
current = current->next;
}
return NULL; // Not found
}
// --- Delete ---
bool ht_delete(HashTable *ht, const char *key) {
unsigned long index = hash_djb2(key) % ht->capacity;
Entry *current = ht->buckets[index];
Entry *prev = NULL;
while (current) {
if (strcmp(current->key, key) == 0) {
if (prev)
prev->next = current->next;
else
ht->buckets[index] = current->next;
free(current->key);
free(current->value);
free(current);
ht->count--;
return true;
}
prev = current;
current = current->next;
}
return false; // Key not found
}
// --- Destroy ---
void ht_destroy(HashTable *ht) {
for (int i = 0; i < ht->capacity; i++) {
Entry *current = ht->buckets[i];
while (current) {
Entry *temp = current;
current = current->next;
free(temp->key);
free(temp->value);
free(temp);
}
}
free(ht->buckets);
free(ht);
}
// --- Print (debug) ---
void ht_print(HashTable *ht) {
printf("Hash Table (%d/%d entries):\n", ht->count, ht->capacity);
for (int i = 0; i < ht->capacity; i++) {
Entry *e = ht->buckets[i];
if (!e) continue;
printf(" [%d]: ", i);
while (e) {
printf("%s=%s ", e->key, e->value);
e = e->next;
}
printf("\n");
}
}
int main(void) {
HashTable *ht = ht_create(INITIAL_CAPACITY);
ht_set(ht, "name", "Chirag");
ht_set(ht, "language", "C");
ht_set(ht, "os", "Linux");
ht_set(ht, "editor", "vim");
printf("name: %s\n", ht_get(ht, "name")); // Chirag
printf("language: %s\n", ht_get(ht, "language")); // C
ht_set(ht, "editor", "neovim"); // Update
printf("editor: %s\n", ht_get(ht, "editor")); // neovim
ht_delete(ht, "os");
printf("os: %s\n", ht_get(ht, "os") ? ht_get(ht, "os") : "NOT FOUND");
ht_print(ht);
ht_destroy(ht);
return 0;
}Key design decisions to notice: we use strdup() to copy keys and values. The hash table owns its copies. This prevents the caller’s strings from being modified or freed out from under us.
Open Addressing: Linear Probing
Instead of linked lists, open addressing stores everything directly in the array. When a collision occurs, you probe forward until you find an empty slot.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define CAPACITY 16
#define DELETED ((char *)-1) // Sentinel for deleted entries
typedef struct {
char *key;
char *value;
} Entry;
typedef struct {
Entry entries[CAPACITY];
int count;
} LinearProbingHT;
static unsigned long hash(const char *str) {
unsigned long h = 5381;
int c;
while ((c = *str++)) h = ((h << 5) + h) + c;
return h;
}
void lp_init(LinearProbingHT *ht) {
memset(ht->entries, 0, sizeof(ht->entries));
ht->count = 0;
}
void lp_set(LinearProbingHT *ht, const char *key, const char *value) {
if (ht->count >= CAPACITY * 3 / 4) {
fprintf(stderr, "Table is too full! Need to resize.\n");
return;
}
unsigned long idx = hash(key) % CAPACITY;
for (int i = 0; i < CAPACITY; i++) {
unsigned long probe = (idx + i) % CAPACITY;
Entry *e = &ht->entries[probe];
if (!e->key || e->key == DELETED) {
// Empty or deleted slot: insert here
e->key = strdup(key);
e->value = strdup(value);
ht->count++;
return;
}
if (strcmp(e->key, key) == 0) {
// Key exists: update
free(e->value);
e->value = strdup(value);
return;
}
}
}
char *lp_get(LinearProbingHT *ht, const char *key) {
unsigned long idx = hash(key) % CAPACITY;
for (int i = 0; i < CAPACITY; i++) {
unsigned long probe = (idx + i) % CAPACITY;
Entry *e = &ht->entries[probe];
if (!e->key) return NULL; // Empty: key doesn't exist
if (e->key == DELETED) continue; // Skip tombstones
if (strcmp(e->key, key) == 0)
return e->value;
}
return NULL;
}
int main(void) {
LinearProbingHT ht;
lp_init(&ht);
lp_set(&ht, "port", "8080");
lp_set(&ht, "host", "localhost");
lp_set(&ht, "protocol", "https");
printf("host: %s\n", lp_get(&ht, "host")); // localhost
printf("port: %s\n", lp_get(&ht, "port")); // 8080
printf("missing: %s\n", lp_get(&ht, "missing") ? lp_get(&ht, "missing") : "NULL");
return 0;
}Linear probing is cache-friendly (elements are in contiguous memory) but suffers from clustering — groups of occupied slots form, making probes longer. Keeping the load factor below 0.75 helps.
Dynamic Resizing and Load Factor
The load factor is count / capacity. When it crosses a threshold (typically 0.75), performance degrades — chains get longer, probes get slower.
The solution: resize the table. Create a new, larger array (usually 2x), then rehash every entry into the new array. Here’s how to add resizing to our chaining implementation:
static void ht_resize(HashTable *ht, int new_capacity) {
Entry **new_buckets = calloc(new_capacity, sizeof(Entry *));
if (!new_buckets) { perror("calloc"); return; }
// Rehash all entries into new buckets
for (int i = 0; i < ht->capacity; i++) {
Entry *current = ht->buckets[i];
while (current) {
Entry *next = current->next;
unsigned long new_index = hash_djb2(current->key) % new_capacity;
current->next = new_buckets[new_index];
new_buckets[new_index] = current;
current = next;
}
}
free(ht->buckets);
ht->buckets = new_buckets;
ht->capacity = new_capacity;
}
// Call this in ht_set() before inserting:
// if ((float)ht->count / ht->capacity > 0.75)
// ht_resize(ht, ht->capacity * 2);Resizing is O(n) since you must rehash everything, but it happens rarely. Amortized over many insertions, each insert is still O(1). This is the same strategy used by dynamic arrays — if you’ve worked with C Arrays, the doubling pattern should feel familiar.
Performance Analysis
| Operation | Average Case | Worst Case |
|---|---|---|
| Insert (set) | O(1) | O(n) |
| Lookup (get) | O(1) | O(n) |
| Delete | O(1) | O(n) |
| Resize | O(n) | O(n) |
The worst case happens when all keys hash to the same bucket, turning the hash table into a linked list. A good hash function and proper load factor management make this extremely unlikely.
Memory usage is approximately capacity * sizeof(Entry*) + count * sizeof(Entry) for chaining, plus the strdup’d key/value strings. It’s a space-time tradeoff — you spend more memory to get O(1) access.
Common Mistakes
1. Not Copying Keys
If you store the caller’s pointer directly instead of using strdup(), the key can change or be freed externally. Your hash table now has a dangling pointer. Always own your copies.
2. Memory Leaks in Destroy
You must free the key, the value, the entry struct, every entry in every chain, the bucket array, and the hash table struct. Miss any one of these and you have a leak. Use valgrind to verify. For more, read C Memory Bugs.
3. Forgetting to Update on Duplicate Keys
If the same key is inserted twice without checking for duplicates, you’ll have two entries with the same key. Lookups will find the first one, and the second becomes unreachable (a leak).
4. Using a Bad Hash Function
A hash function that returns the same value for many inputs (like always returning 0) defeats the entire purpose. Test your hash function with varied inputs.
5. Not Resizing
A hash table that never resizes will degrade to O(n) as the load factor approaches 1.0. Monitor your load factor and resize at 0.75.
Practice Exercises
- Word frequency counter: Read a text file and count how many times each word appears using a hash table. Print the top 10 most frequent words.
- Two Sum problem: Given an array of integers and a target, find two numbers that add up to the target. Use a hash table for O(n) solution instead of the brute-force O(n²).
- Implement
ht_keys()andht_values()functions that return arrays of all keys and values in the hash table. - Add integer values: Modify the hash table to store
intvalues instead of strings. Implementht_increment(key)that increments the value for a key (inserting 1 if the key doesn’t exist). - Implement open addressing with quadratic probing: Instead of probing at
idx + 1, idx + 2, idx + 3..., probe atidx + 1, idx + 4, idx + 9...(squares). Compare clustering behavior with linear probing. - Build a simple spell checker: Load a dictionary file into a hash table. Read user input and flag words not found in the dictionary. For each flagged word, suggest corrections by checking single-character edits against the dictionary. This requires understanding C Strings for string manipulation.
Hash tables are one of the most practical data structures you’ll ever implement. They bridge the gap between “I learned C syntax” and “I can build real systems.” Keep going with the C Programming Roadmap to tackle trees, graphs, and more.